Af Tobias Morville, Head of Machine Learning.
Kom godt i gang med Machine Learning kan synes at være en overvældende opgave, hvis data er ufuldstændige, investeringsafkastet forventes med det samme og forretningsetik ikke diskuteres. Tidlige eksperimenter og en langsigtet strategi kan dog hjælpe med at etablere en konkurrencefordel og hjælpe beslutningstagere med at omdanne data til forretningskritiske løsninger.
I denne artikel vil du lære om nedenstående:
- Hvorfor langsigtet succes med Machine Learning kræver tidlige og målrettede eksperimenter, der fejler hurtigt.
- Hvordan nye teknologier giver bedre data til beslutningstagning.
- Det væsentlige ved Machine Learning, og hvordan den adskiller sig fra nuværende forsikringsberegningsmodeller.
- Sådan kommer du i gang og høster den skjulte værdi i dine data.
Her er et eksempel til at illustrere min pointe:
Ifølge en rapport fra Teradata gør 80% af virksomhederne, der investeres i Marchine Learning eller forskellige grene af AI, det for at forbedre kundeoplevelsen, minimere omkostninger eller styre risici. For forsikringsselskaber bidrager to grundlæggende drivere til vedtagelsen af ny teknologi:

Implementering af ny teknologi er kun det første skridt i at høste fordelene ved digital. Ofte ledsages anvendelsen af Machine Learning metoder af en stigning i omkostningerne, en åbenbar mangel på resultater og masser af frustrationer. At indstille de rigtige forventninger fra starten er afgørende for senere succes.
Langsigtet succes kræver tidlig maskineindlæring
Oftere end ikke vil vedtagelse af Machine Learning ikke give øjeblikkelige afkast. Faktisk er tidlig implementering af Machine Learning forbundet med en stigning i omkostningerne og kræver en langsigtet strategi for at gøre dem til fortjeneste. Dette skyldes kravene til datakvalitet og teknologiens udforskende natur.
”
Ifølge en BCG-analyse ser mere end halvdelen af de virksomheder, der investerer i maskinlæring, ikke vende tilbage til investering.”
– Tobias Lund-Eskerod, Delivery Director, Monstarlab
“
Hvis data ikke er repræsentative, er dine modeller slået fra. I de tidlige stadier finder du ofte ufuldstændige datasæt, som enten skal være komplette, eller det problem, du prøver at løse, skal ændres ”siger Tobias Lund-Eskerod, Delivery Director hos Monstarlab og fortsætter:
”Når teknologien anvendes, vil uventede fund meget sandsynligt vises. Disse fund kan have stor indflydelse på det tildelte budget til projektet, hvilket gør det vanskeligt at overbevise alle om dets potentiale ”. Men håndtering af de økonomiske omkostninger ved Machine Learning synes at være lige så vigtig som den potentielle fortjeneste, når man spørger it-beslutningstagere. Ifølge Teradata forventer virksomheder, der har vedtaget Machine Learning teknologien, et betydeligt investeringsafkast i fremtiden:
Forventet investeringsafkast for hver dollar, der investeres i AI-teknologier
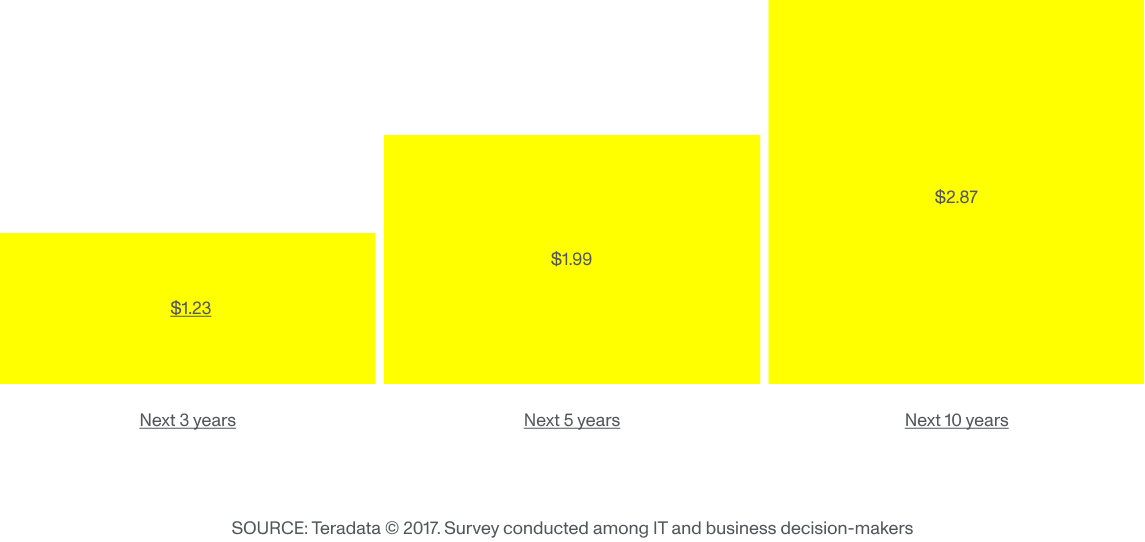
Da ledere aspekterer ROI til tredobling på 10 år, er behovet for en langsigtet strategi med kontinuerlige investeringer, flere tests og evalueringer afgørende. Alligevel har erhvervsledere svært ved at forpligte sig fuldt ud til teknologien på grund af den succesrige forretningsmodel inden for forsikring med høje margener og stabilitet i årtier. Demystificering af ML er afgørende for større og tidligere adoption.
Styrke beslutningstagere ved at afsløre nye oplysninger
Uddannelse af forudsigelige modeller til at behandle manuelle opgaver og finde mønstre i strukturerede, semistrukturerede og ustrukturerede datasæt for at skabe bedre forretningsbeslutninger er betagende for alle forsikringsselskaber. Men virkeligheden er, at selvom de har masser af kundedata, er nogle forsigtige med det potentielle resultat, når de anvender Machine Learning teknologi.
”Selve kernen i et forsikringsselskab er at vurdere risici baseret på personlige oplysninger og oprette matchende politikker. Og fordi vi alle er individer, rummer Machine Learning potentialet i at behandle os alle forskelligt fra hinanden, hvilket åbner op for diskrimination ”, siger Tobias Lund-Eskerod.
En vigtig del af ethvert forsikringsselskab er at opdele hele deres kundebase i mindre grupper. Men Machine Learning rummer potentialet i at nedbryde grupper til en gruppe på meget få og vurdere individer ud fra uhensigtsmæssige kriterier såsom race, køn, seksuel orientering osv.
Men selv med denne integrerede risiko for Machine Learning er teknologien stadig baseret på data og matematiske metoder, siger Tobias Lund-Eskerod. Data, som forsikringsselskaberne vælger, renser og forbereder samt matematiske metoder som regression, klassificering og klyngedannelse. Hvordan forsikringsselskaber beslutter at fortolke resultatet, er helt op til virksomhedslederne. Teknologien i sig selv har ikke magten til at diskriminere, stille spørgsmål eller løse problemer. Det har dog potentialet til at minimere omkostninger, øge overskuddet og især udføre en mere præcis beregning af kundelivets værdi med minimal menneskelig indgriben og vejledning.
Anvendelse af Machine Learning for at forbedre kundelivets værdi – eksempel
Machine learning er kun så god som de præsenterede data. Men med forsikringsselskaber, der kun behandler 10-15% af deres kundeoplysninger, ifølge en Accenture-undersøgelse, undlader forsikringsselskaberne at bruge deres indsigt til at beregne præcise CLV’er for deres kunder. Indsigt, der kan styrke værdifulde politikker for både forsikringsselskabet og forsikrede.
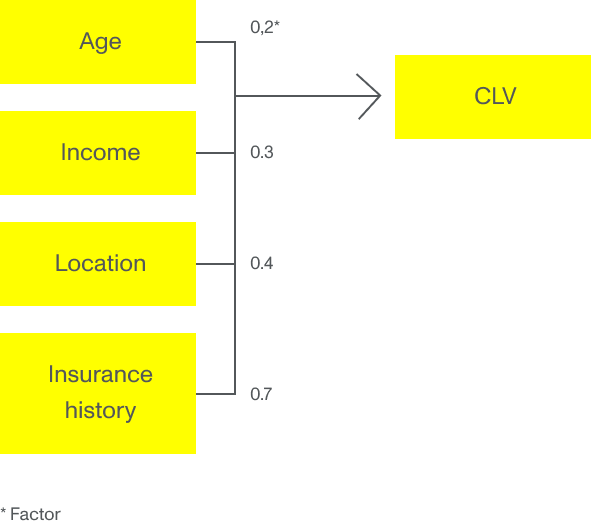
En almindelig praksis for forsikringsselskaber er at bruge alder, bopæl, eksterne sociodemografiske parametre som input til prisfastsættelse og CLV-bestemmelse. Disse parametre bruges ofte i en GLM eller multiple lineær regressionsmodel, hvor hver input får en faktor, som har indflydelse på CLV. For eksempel svarer en ung kunde i et stille kvarter til en højere forventet CLV end en ung kunde i et kvarter, der statistisk er tilbøjelig til tyveri.
Men forestil dig, om sammenhængen var anderledes. Forestil dig, at hvis den unge kunde, der bor i nabolaget statistisk udsat for tyveri, ikke er så sandsynlig at udfylde et forsikringskrav som den multiple lineære regressionsmodel indikerer. Hvis vi anvender Machine Learnings algoritmer til dette eksempel, fodrer vi algoritmen med masser af historiske data om kunder samlet over tid af forsikringsselskabet, statistiske databaser og offentlige organisationer. Præsenteret med alle disse data kan Machine Learnings modeller identificere underliggende mønstre og opdage de parametre, der virkelig betyder noget for beregning af en mere præcis CLV. Den vigtigste parameter for den unge kunde i det urolige kvarter er måske ikke placeringen, men snarere uddannelse, civilstand eller antallet af forsikringspolicer – eller endda alle sammen.
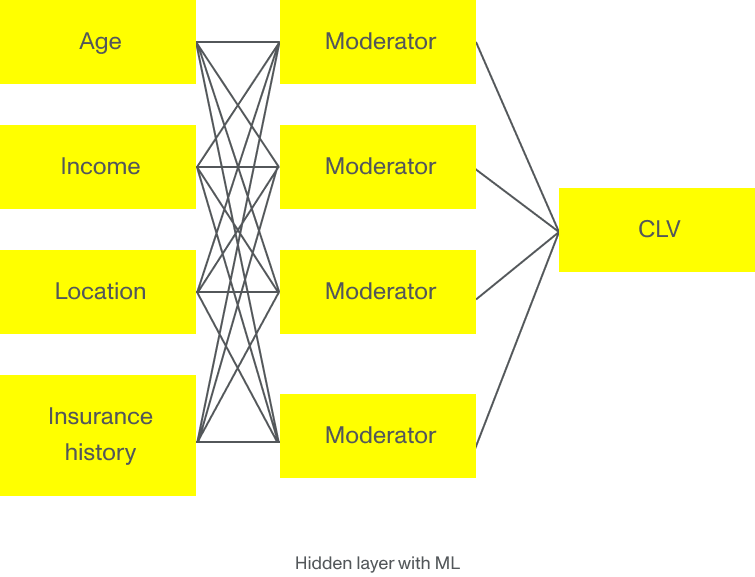
Kompleksiteten og den store mængde information, der præsenteres, er simpelthen for meget til, at flere regressionsmodeller kan dække. Det er her nye teknologier som Machine Learning og dyb læring viser sin rette vægt ved at skabe en mere nøjagtig vurdering og forudsigelse af kunderne.
Sådan kommer du i gang med Machine Learning
Selvom forsikringsselskaber har oplevet rentable margener og en bæredygtig forretningsmodel i mange årtier, tror et flertal af forretningsledere, at de skal indarbejde nye teknologier for at forblive relevante for deres kunder.
En almindelig praksis for forsikringsselskaber er at bruge alder, bopæl, eksterne sociodemografiske parametre som input til prisfastsættelse og CLV-bestemmelse. Disse parametre bruges ofte i en GLM eller multiple lineær regressionsmodel, hvor hver input får en faktor, som har indflydelse på CLV. For eksempel svarer en ung kunde i et stille kvarter til en højere forventet CLV end en ung kunde i et kvarter, der statistisk er tilbøjelig til tyveri.
”Ifølge en undersøgelse fra 2018 mener 82% af virksomhedsledere i forsikringssektoren, at de skal være innovative for at opretholde en konkurrencemæssig fordel. Alligevel tilføjer 77% af dem, at teknologien udvikler sig hurtigere, end hvad deres virksomhed kan tilpasse sig, ” siger Tobias Lund-Eskerod.
Med andre ord er det vigtigt at blive fortrolig med Machine Learning nu for at forblive relevant i det digitale skiftende landskab. Men at komme i gang kan føles som at kigge efter en nål i en høstak. For at få hjulene til at dreje, bør beslutningstagere i forsikringsselskaber starte Machine Learnings-rejsen ved at besvare disse tre spørgsmål: