Autor: Tobias Morville, vedoucí oddělení strojového učení.
Začít pracovat s modely strojového učení se může zdát jako nadlidský úkol, pokud jsou data neúplná, návratnost investic se očekává okamžitě a obchodní etika zůstává neoddiskutována. Včasné experimenty a dlouhodobá strategie však mohou pomoci vytvořit konkurenční výhodu a pomoci rozhodujícím pracovníkům transformovat data do kritických obchodních řešení.
V tomto článku se dozvíte:
- Proč dlouhodobý úspěch strojového učení vyžaduje včasné a cílené experimentování, které rychle selže.
- Jak nové technologie poskytují lepší data pro rozhodování.
- Základy strojového učení a jeho odlišnosti od současných modelů výpočtu pojištění.
- Jak začít a využít skrytou hodnotu svých dat.
Pro ilustraci uvádím příklad:
Podle zprávy společnosti Teradata 80 % podniků, které investují do strojového učení nebo různých odvětví umělé inteligence, tak činí za účelem zlepšení zákaznické zkušenosti, minimalizace nákladů nebo řízení rizik. U pojišťoven přispívají k zavádění nových technologií dva základní faktory:

Zavedení nové technologie je pouze prvním krokem k plnému využití výhod digitálních technologií. Aplikaci metodik strojového učení často provází nárůst nákladů, zjevný nedostatek výsledků a spousta frustrací. Nastavení správných očekávání od začátku je klíčové pro pozdější úspěch.
Dlouhodobý úspěch vyžaduje včasné experimentování se strojovým učením
Přijetí strojového učení nejčastěji nepřinese okamžitou návratnost. Ve skutečnosti je brzké zavedení strojového učení spojeno se zvýšením nákladů a vyžaduje dlouhodobou strategii, která je promění v zisk. Důvodem jsou požadavky na kvalitu dat a průzkumná povaha této technologie.
„Podle analýzy BCG více než polovina společností, které investují do strojového učení, nevidí žádnou návratnost investic.“
– Tobias Lund-Eskerod, ředitel pro dodávky, Monstarlab
„Pokud data nejsou reprezentativní, vaše modely budou chybné. V počátečních fázích se často setkáte s neúplnými soubory dat, které se buď musí stát úplnými, nebo se musí změnit problém, který se snažíte vyřešit,“ říká Tobias Lund-Eskerod, ředitel pro dodávky ve společnosti Monstarlab, a pokračuje:
„Při použití této technologie se velmi pravděpodobně objeví neočekávaná zjištění. Tato zjištění mohou mít velký dopad na přidělený rozpočet projektu, takže je obtížné všechny přesvědčit o jeho potenciálu.“ Zdá se však, že řešení finančních nákladů na strojové učení je stejně důležité jako potenciální zisk, když se ptáte těch, kteří rozhodují o IT. Podle společnosti Teradata firmy, které přijaly technologii strojového učení, očekávají v budoucnu významnou návratnost investic:
Očekávaná návratnost investic do technologií umělé inteligence na každý investovaný dolar
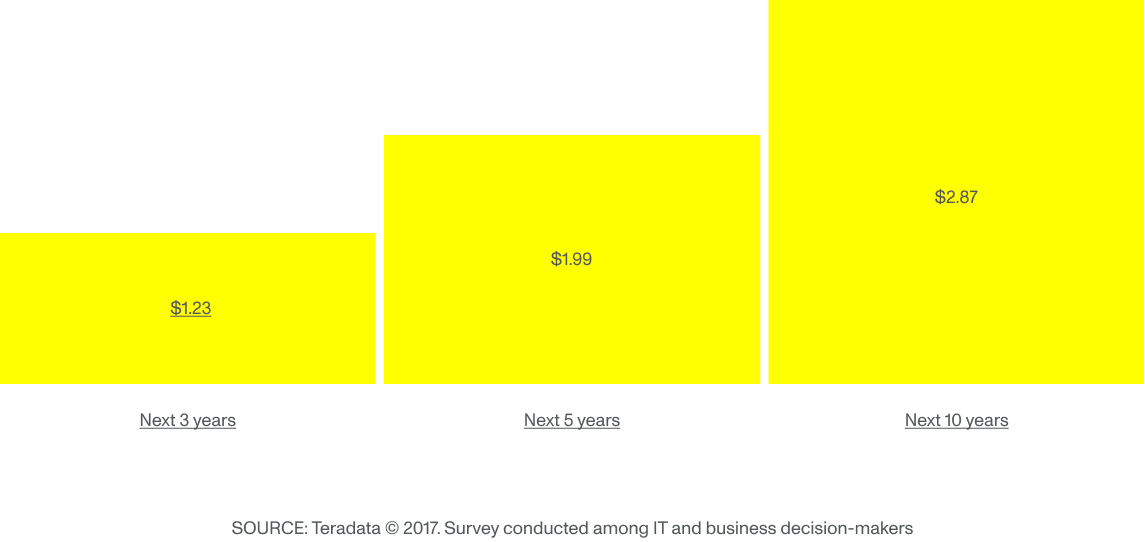
Vzhledem k tomu, že vedoucí pracovníci očekávají ztrojnásobení návratnosti investic do 10 let, je potřeba dlouhodobé strategie s průběžnými investicemi, vícenásobným testováním a hodnocením zásadní. Přesto je pro vedoucí pracovníky podniků obtížné se této technologii plně věnovat, a to vzhledem k úspěšnému obchodnímu modelu v pojišťovnictví s vysokými maržemi a stabilitou po celá desetiletí. Demystifikace strojového učení (ML) je rozhodující pro větší a dřívější přijetí.
Posílení osob s rozhodovací pravomocí odhalením nových informací
Trénování prediktivních modelů pro zpracování manuálních úloh a hledání vzorů ve strukturovaných, polostrukturovaných a nestrukturovaných souborech dat pro lepší obchodní rozhodování je zajímavé pro všechny pojišťovny. Skutečnost je však taková, že i když mají k dispozici tuny zákaznických dat, některé z nich se obávají možných výsledků při použití technologie strojového učení.
„Podstatou pojišťovny je vyhodnocovat rizika na základě osobních údajů a vytvářet odpovídající pojistky. A protože každý z nás je individualitou, strojové učení v sobě skrývá potenciál přistupovat ke každému z nás jinak, což otevírá prostor pro diskriminaci,“ říká Tobias Lund-Eskerod.
Důležitou součástí každé pojišťovny je rozdělení celé zákaznické základny na menší skupiny. Strojové učení však v sobě skrývá potenciál vytvořit dělením velmi malé skupiny a posuzovat jednotlivce na základě nevhodných kritérií, jako je rasa, pohlaví, sexuální orientace atd.
Ale i přes toto nedílné riziko strojového učení je tato technologie stále založena na datech a matematických metodikách, říká Tobias Lund-Eskerod. Data, která pojišťovatelé vybírají, čistí a připravují, a také matematické metodiky, jako je regrese, klasifikace a shlukování. Jak se pojišťovatelé rozhodnou interpretovat výsledek, záleží pouze na vedoucích představitelích podniku. Technologie sama o sobě nemá sílu rozlišovat, klást otázky nebo řešit problémy. Má však potenciál minimalizovat náklady, zvyšovat zisky a zejména provádět přesnější výpočty hodnoty života zákazníka (Customer Life Value, CLV) s minimálním lidským zásahem a vedením.
Aplikace strojového učení na hodnotu života zákazníka – příklad
Strojové učení je jen tak dobré, jak dobrá jsou předložená data. Podle průzkumu společnosti Accenture však pojišťovny zpracovávají pouze 10-15 % informací o svých zákaznících, a proto se jim nedaří využít své poznatky k přesnému výpočtu CLV pro své zákazníky. Poznatky, které by mohly posílit cenné pojistné smlouvy pro pojistitele i pojištěné.
Běžnou praxí pojistitelů je používat věk, bydliště a vnější sociodemografické parametry jako vstupní údaje pro stanovení ceny a CLV. Tyto parametry se často používají v modelu GLM nebo vícenásobné lineární regrese, kde je každému vstupu přiřazen faktor, který má vliv na CLV. Například mladý zákazník v klidné čtvrti bude mít vyšší očekávané CLV než mladý zákazník ve čtvrti statisticky náchylné ke krádežím.
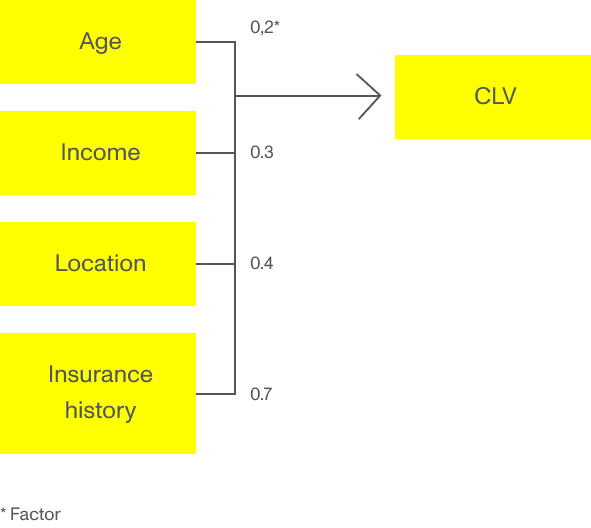
Představte si ale, že by korelace byla jiná. Představte si, že mladý zákazník žijící ve čtvrti statisticky náchylné ke krádežím nevyplňuje pojistnou událost s takovou pravděpodobností, jak ukazuje model vícenásobné lineární regrese. Pokud na tento příklad aplikujeme algoritmy strojového učení, dodáme algoritmu spoustu historických dat o zákaznících, která v průběhu času shromáždila pojišťovna, statistické databáze a vládní organizace. Pokud jim předložíme všechna tato data, modely strojového učení mohou identifikovat základní vzorce a objevit ty parametry, které jsou skutečně důležité pro přesnější výpočet CLV. Tím nejdůležitějším parametrem u mladého zákazníka z problémové čtvrti nemusí být lokalita, ale spíše vzdělání, rodinný stav nebo počet pojistných smluv – nebo dokonce všechny dohromady.
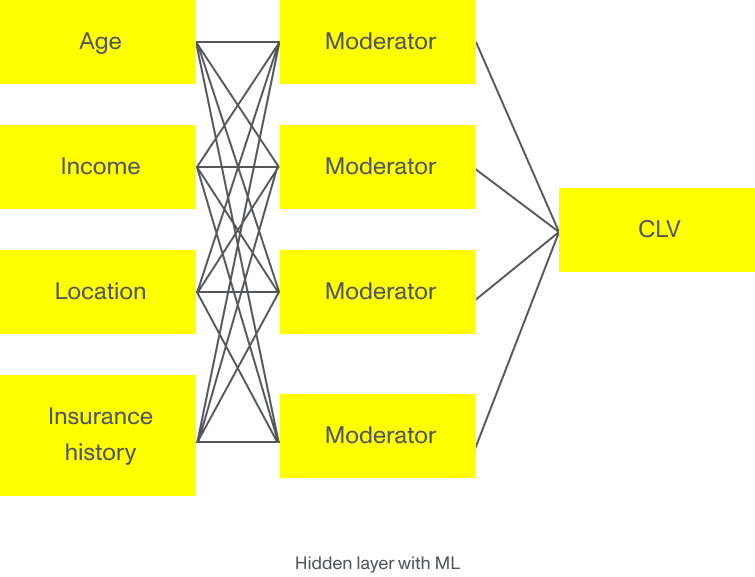
Složitost a obrovské množství prezentovaných informací jsou prostě příliš velké na to, aby je pokryly vícenásobné regresní modely. Zde se projevují nové technologie, jako je strojové učení a hluboké učení, které umožňují přesnější hodnocení a predikci zákazníků.
Jak začít se strojovým učením
Přestože pojišťovny si užívají ziskové marže a udržitelný obchodní model již mnoho desetiletí, většina vedoucích pracovníků těchto firem se domnívá, že musí začlenit nové technologie, aby zůstaly pro své zákazníky relevantní.
Běžnou praxí pojistitelů je používat věk, bydliště a vnější sociodemografické parametry jako vstupní údaje pro stanovení ceny a CLV. Tyto parametry se často používají v modelu GLM nebo vícenásobné lineární regrese, kde je každému vstupu přiřazen faktor, který má vliv na CLV. Například mladý zákazník v klidné čtvrti bude mít vyšší očekávané CLV než mladý zákazník ve čtvrti statisticky náchylné ke krádežím.
„Podle studie z roku 2018 se 82 % vedoucích pracovníků v pojišťovnictví domnívá, že musí být inovativní, aby si udrželi konkurenční výhodu. Přesto 77 % z nich dodává, že technologie se vyvíjejí rychleji, než se jim jejich společnost dokáže přizpůsobit,“ říká Tobias Lund-Eskerod.
Jinými slovy, seznámení se strojovým učením je důležité již nyní, abyste si udrželi relevanci v neustále se měnícím digitálním prostředí. Začátky však mohou připomínat hledání jehly v kupce sena. Aby se rozhodovací orgány v pojišťovnách roztočily, měly by začít cestu strojového učení tím, že si odpoví na tyto tři otázky: